Brief Article Teaches You The Ins and Outs of Deepseek Chatgpt And Wha…
페이지 정보

본문
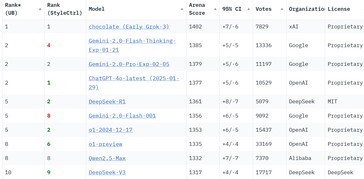 This dynamic highlights the position of hypothesis in driving innovation, though it can also result in market instability. While OpenAI’s o4 continues to be the state-of-artwork AI model available in the market, it is just a matter of time earlier than other models might take the lead in constructing super intelligence. In keeping with benchmark information on each fashions on LiveBench, in terms of overall performance, the o1 edges out R1 with a worldwide common rating of 75.67 in comparison with the Chinese model’s 71.38. OpenAI’s o1 continues to carry out properly on reasoning tasks with a nearly 9-point lead towards its competitor, making it a go-to choice for complex problem-fixing, vital considering and language-related duties. DeepSeek, by its distillation course of, exhibits that it will probably successfully transfers the reasoning patterns of larger fashions into smaller models. LLMs Can Easily Learn to Reason from Demonstrations Structure, not content material, is what matters! LLMs. Microsoft-backed OpenAI cultivated a brand new crop of reasoning chatbots with its ‘O’ sequence that have been higher than ChatGPT. After seeing early success in DeepSeek online-v3, High-Flyer built its most superior reasoning models - - DeepSeek-R1-Zero and DeepSeek-R1 - - which have doubtlessly disrupted the AI trade by becoming one of the vital value-environment friendly models out there.
This dynamic highlights the position of hypothesis in driving innovation, though it can also result in market instability. While OpenAI’s o4 continues to be the state-of-artwork AI model available in the market, it is just a matter of time earlier than other models might take the lead in constructing super intelligence. In keeping with benchmark information on each fashions on LiveBench, in terms of overall performance, the o1 edges out R1 with a worldwide common rating of 75.67 in comparison with the Chinese model’s 71.38. OpenAI’s o1 continues to carry out properly on reasoning tasks with a nearly 9-point lead towards its competitor, making it a go-to choice for complex problem-fixing, vital considering and language-related duties. DeepSeek, by its distillation course of, exhibits that it will probably successfully transfers the reasoning patterns of larger fashions into smaller models. LLMs Can Easily Learn to Reason from Demonstrations Structure, not content material, is what matters! LLMs. Microsoft-backed OpenAI cultivated a brand new crop of reasoning chatbots with its ‘O’ sequence that have been higher than ChatGPT. After seeing early success in DeepSeek online-v3, High-Flyer built its most superior reasoning models - - DeepSeek-R1-Zero and DeepSeek-R1 - - which have doubtlessly disrupted the AI trade by becoming one of the vital value-environment friendly models out there.
 This implies, instead of coaching smaller fashions from scratch using reinforcement studying (RL), which can be computationally expensive, the knowledge and reasoning abilities acquired by a larger model might be transferred to smaller fashions, leading to better efficiency. Accessing the underlying code and model parameters allows customers to implement customized coaching routines, integrate specialised datasets, and optimize for area of interest vocabularies. AI area early sufficient." Mr. Schmidt further pointed out that lack of training data on language and China’s unfamiliarity with open-supply ideas could make the Chinese fall behind in world AI race. For over two years, San Francisco-based OpenAI has dominated synthetic intelligence (AI) with its generative pre-trained language models. App Store over the weekend. Ernie was touted as the China’s reply to ChatGPT after the bot acquired over 30 million consumer sign-ups within a day of its launch. But the initial euphoria around Ernie progressively ebbed as the bot fumbled and dodged questions on China’s President Xi Jinping, the Tiananmen Square crackdown and the human rights violation towards the Uyghur Muslims. The implications thus lengthen far beyond expertise, raising pressing questions about the long run of worldwide AI governance, economic competitors, and safety stability.
This implies, instead of coaching smaller fashions from scratch using reinforcement studying (RL), which can be computationally expensive, the knowledge and reasoning abilities acquired by a larger model might be transferred to smaller fashions, leading to better efficiency. Accessing the underlying code and model parameters allows customers to implement customized coaching routines, integrate specialised datasets, and optimize for area of interest vocabularies. AI area early sufficient." Mr. Schmidt further pointed out that lack of training data on language and China’s unfamiliarity with open-supply ideas could make the Chinese fall behind in world AI race. For over two years, San Francisco-based OpenAI has dominated synthetic intelligence (AI) with its generative pre-trained language models. App Store over the weekend. Ernie was touted as the China’s reply to ChatGPT after the bot acquired over 30 million consumer sign-ups within a day of its launch. But the initial euphoria around Ernie progressively ebbed as the bot fumbled and dodged questions on China’s President Xi Jinping, the Tiananmen Square crackdown and the human rights violation towards the Uyghur Muslims. The implications thus lengthen far beyond expertise, raising pressing questions about the long run of worldwide AI governance, economic competitors, and safety stability.
What does this mean for the future of labor? This, in essence, would imply that inference could shift to the sting, changing the landscape of AI infrastructure firms as more environment friendly fashions might cut back reliance on centralised information centres. Given how fast AI companies are transferring, I wouldn’t be shocked if these features were added quickly. That is a part of what I was getting at by "we’re going to see LLMs grow to be the BATNA for social interaction." In the event you, personally, need humans to speak to other humans more, you, personally, are going to have to determine how to make people higher at it. As the hype around Ernie met the truth of Chinese censorship, a number of consultants pointed out the problem of constructing large language models (LLMs) in the communist nation. Also bringing out the fear beads in Silicon Valley, DeepSeek has been round for lower than two years and is the brainchild of 39-12 months old Liang Wenfeng, a computer wizard who started a quant hedge fund at age 25 which had garnered a $39 billion portfolio eleven years later, in accordance with Reuters.
Specifically, a 32 billion parameter base model skilled with large scale RL achieved performance on par with QwQ-32B-Preview, whereas the distilled model, DeepSeek-R1-Distill-Qwen-32B, performed considerably higher across all benchmarks. The Mixture-of-Expert (MoE) model was pre-skilled on 14.8 trillion tokens with 671 billion complete parameters of which 37 billion are activated for every token. Censorship Concerns: Being developed in a very regulated setting also means some delicate answers are suppressed. Whether or not that bundle of controls might be effective stays to be seen, however there's a broader level that each the current and incoming presidential administrations need to grasp: speedy, simple, and frequently updated export controls are way more prone to be more effective than even an exquisitely complicated effectively-outlined policy that comes too late. Nvidia itself acknowledged DeepSeek's achievement, emphasizing that it aligns with US export controls and shows new approaches to AI mannequin growth. However, like different Chinese artificial intelligence chatbots working underneath China's regulatory framework, Free DeepSeek Chat's responses to politically delicate subjects reveal clear limitations.
- 이전글Esl college admission paper example 25.02.28
- 다음글5 Suggestions For Host A Wonderful Karaoke Contest Party 25.02.28
댓글목록
등록된 댓글이 없습니다.